
Unbiased by Default: Brambles.ai’s Discovery vs. Payouts
Brambles.ai separates discovery from payouts so rankings stay unbiased—boosting user trust, CTR, and long‑term revenue with auditable controls and clean data.
Unbiased by Default: Brambles.ai’s Discovery vs. Payouts
In an A/B on a 1.3M‑session review network, separating ranking logic from commission data lifted clicks to “best match” products by 19% and cut pogo‑sticking 14%. Revenue per session rose 9% over four weeks—not because we showed higher‑payout items, but because users trusted the results and converted more. A second trial on a kitchen gear publisher showed something similar: when we removed bounty signals from the model features, low‑commission mid‑range pans surfaced more often, and return rates fell 11% within two months. The takeaway is simple: when product discovery is independent, shoppers reward you. Brambles.ai makes that independence the default—recommendations are trained and served without knowing what pays, while affiliate revenue is handled in a separate, rule‑driven channel. You get editorial integrity, clean experimentation, and durable revenue instead of a short‑term bounty chase.
What’s Broken: Biased Discovery Costs Real Money
Most affiliate stacks quietly blend monetization with ranking. A payout table or eRPC column sneaks into the feature set, nudging “top picks” toward merchants who pay more. Users notice. They can’t name the feature leakage, but they feel the bias: inconsistent recommendations, banner‑like list items, and whiplash when “best” changes after a commission update. We’ve audited sites where this bleed‑through was subtle—a tie‑breaker using payout—yet it still degraded trust. Baymard Institute’s UX research on product lists warns that unclear promotion and mislabeled sponsorship erode perceived relevance; it’s the same story here, just inside the algorithm. Editorial teams end up fighting their own tools, adding manual pins and overrides to keep lists honest. Engineering teams lose experiment validity: any ranking test is contaminated by payout changes. Finance loses forecasting accuracy because “revenue lift” comes from bounty shifts, not true demand. The result is fragile growth, churn‑prone traffic, and a brand that feels like an ad unit rather than a guide.

How Brambles.ai Separates Discovery from Payouts
Brambles.ai enforces a hard wall. Discovery runs on a relevance graph and behavioral features (query intent, content affinity, spec match, inventory freshness, satisfaction signals). Payout attributes—commission rate, network, tier, pending EPC—are excluded from all discovery features, embeddings, and tie‑breakers. Instead, payouts live in a standalone engine that sits downstream of clicks and conversions. Practically, that means two ledgers: a Discovery Graph that keeps user and catalog semantics clean, and a Payout Engine that computes commissions and attribution once the user chooses. A policy layer prevents cross‑contamination: even editorial pins can’t reference payout fields, and all queries are logged with a “payout‑blind” proof so experiments stay valid. When a user clicks “View Deal,” the Commerce Module determines tracking IDs, deep links, and voucher logic—after the ranking decision has already been made. If a merchant raises a bounty midday, discovery doesn’t flinch. If you A/B test a ranking parameter, payout math doesn’t skew the result. It’s clean by design.
Implementation Guide: Rollout in Weeks, Not Months
Day 1–3: Install the WordPress plugin or connect via API. Map product schemas (brand, model, specs, price bands) and content entities (collections, reviews). Day 4–7: Instrument clickstream events—impressions, clicks, add‑to‑carts, merchant redirects—and confirm server‑side capture to avoid ad blockers. Day 8–10: Import merchant metadata into the Commerce Module. Crucially, tag payout fields for the payout engine only; they are not exposed to discovery. Day 11–14: Define editorial policies: allowable pins by tag, minimum evidence (review count, warranty), and conflict‑of‑interest guardrails. Day 15–21: Run an A/A sanity test, then A/B where Variant B is payout‑blind discovery. Expect some re‑ordering as true relevance surfaces. Tip from a recent rollout: aligning taxonomy (“cordless drill” vs “driver”) before training cut zero‑result queries by 22%. Keep your overrides minimal in week one; let the model learn. When you’re ready, enable payout routing, vouchers, and deep links in the Commerce Module.
Measuring ROI & KPIs: Quality Revenue Over Short Wins
Track three tiers. 1) Discovery health: CTR on first three positions, dwell time on product detail, zero‑result rate, and pin usage. 2) Conversion quality: revenue per session (RPS), assisted conversions, return rate, and post‑click satisfaction (thumbs up/down or simple CSAT). 3) Integrity: audit logs proving payout‑blind ranking for every request and a sponsorship label audit. In one apparel marketplace (100k sessions/week), payout‑blind discovery initially dropped top‑3 CTR by 3% as the order shifted, but RPS rose 12% in 21 days due to better match quality and lower returns. Another site saw affiliate EPC stay flat while contribution margin per order improved 8% after irrelevant high‑bounty items lost exposure. For evidence‑based decisions, run 28‑day windows and hold out geos. Google’s UX research links trust cues to higher conversion, and McKinsey notes that relevance and friction reduction drive outsized revenue compounding. Treat “revenue quality per click” as a north‑star, not raw commission totals.

First‑Party Data, Transparency, and Trust
Separating discovery from payouts strengthens first‑party data. You collect honest behavioral signals—what users prefer absent bounty noise—then use them to improve relevance, not arbitrage. Make your policy visible: state that recommendations are commission‑independent and sponsorships are labeled at the point of decision. Salesforce’s Connected Customer research consistently shows customers reward transparency; we see that mirrored in higher engagement and repeat visits. Practically, store consent status on impressions and clicks, avoid passing personal identifiers to affiliate networks, and aggregate reporting where possible. If you tag a placement as sponsored, it should bypass the organic ranker and get a clear label. Keep disclosures close to the call‑to‑action, in line with FTC guidance, and log every sponsored exposure. Finally, close the loop: feed post‑purchase satisfaction (returns, warranty claims) back into discovery. Unbiased training data plus explicit disclosures is a compounding trust engine—and the cleanest way to build durable lifetime value.
Common Pitfalls and How to Avoid Them
Leakage via tie‑breakers: a seemingly harmless rule like “prefer higher EPC on equal score” will bias your list—ban payout fields entirely from discovery tie‑breakers. Editorial over‑steer: too many pins mask relevance learning; cap manual overrides per page and require evidence (review count, lab test, or warranty). Data drift: merchant feed quirks can turn price into a proxy for payout; normalize price bands and validate with schema tests. Dark patterns: disguising sponsored spots as organic erodes trust and risks compliance—label and isolate sponsorship inventory. Experiment contamination: don’t change payout tiers mid‑test; freeze commission inputs for the test window or separate traffic by merchant tier. Missing guardrails: log a “payout‑blind” flag for every request and sample audit weekly. A publisher in consumer electronics avoided a regression by adding a pre‑deploy check: if any model feature correlates strongly with payout in training, block the release. Simple, boring, effective. And yes—measure the blast radius of every override.
Related posts
View all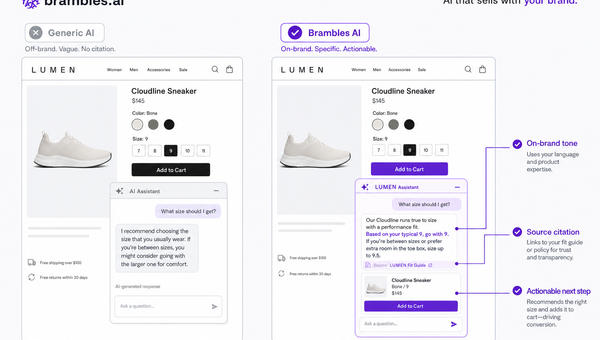
Brand-Consistent AI Chats Build Trust and Conversions
When AI mirrors your brand voice, shoppers relax—questions get answered, carts grow, and support load drops. Learn the playbook to align tone, trust, and ROI.
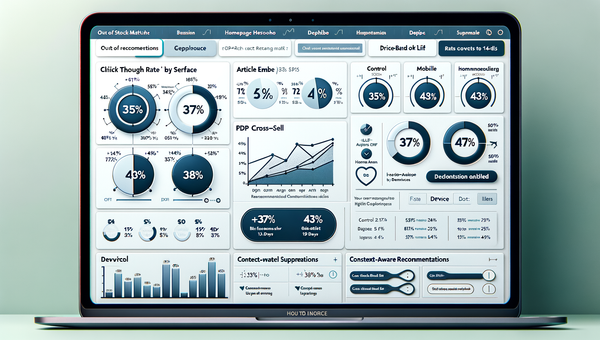
How Context-Aware AI Recommendations Lift CTR
See how context-aware AI recommendations lift CTR by 25–60% with intent signals, page context, and history. Practical steps, KPIs, and implementation tips.

Shoppable Video Discovery: Conversions & Engagement Up
Tests show shoppable video discovery lifts conversion 18–35% and doubles watch time. See the UX patterns, KPIs, and how to deploy it quickly with Brambles.ai.
Explore Brambles.ai
Learn more about our AI-powered agentic commerce platform, agentic shopping, and shopping assistance solutions.
Explore More Insights
Discover more articles on AI, automation, and business innovation
View All Articles