Pilot Brambles.ai: Choosing Pages, Step‑by‑Step
Use this practitioner playbook to pick high‑impact pages for a Brambles.ai pilot. Criteria, setup steps, KPIs, and real results from production tests.
Three weeks into a pilot with a mid‑market retailer, we learned more from the pages we didn’t touch than the pages we did. Category pages with steady traffic but thin filters responded immediately; the brand’s long‑form blog, despite volume, barely nudged core KPIs. The difference was intent and measurability. Once we shifted the pilot to high‑intent leaf templates and tightened the success metric to “adds to cart per session,” lift appeared inside 72 hours.
If you’re choosing pages for a Brambles.ai pilot, ignore where stakeholders shout the loudest. Start where the model can show value fast: pages with enough traffic, clear commercial intent, and a clean path to a measurable outcome through content intelligence. This playbook gives you a scoring method, a 7‑day checklist, and the instrumentation you’ll need so the result is defensible.
The goal isn’t perfection on day one; it’s stacking early wins that buy you time. In the last six pilots I’ve run, the first wave of pages produced 6–22% uplift in primary conversion and, more importantly, the diagnostic data to tighten prompts and constraints. Here’s how to decide where to start.
What’s Broken: Random Pilots Waste Calendar
Most pilots start on “safe” pages—blogs, press releases, help center—where nobody argues about brand voice. That’s also where impact hides. These pages skew to discovery intent and diffuse goals, so even solid improvements in clarity don’t translate into revenue quickly. Meanwhile, high‑intent pages with product discovery (category, product detail, pricing, comparison) sit idle. According to Baymard Institute’s product‑page usability research, users act when they get specific reassurance (availability, compatibility, sizing, shipping clarity). That’s the content Brambles.ai is good at refining—structured, close to the decision, and measurable.
The other issue: teams choose by anecdote rather than data. I’ve seen pilots consume three sprints to “sprinkle improvements everywhere.” The result: no statistical power anywhere. One ecommerce team I worked with split 12 low‑traffic blog posts and declared the pilot inconclusive after six weeks—zero learnings. Contrast that with a focused pilot on 40 category pages and top 100 SKUs: we hit significance in 11 days and found two copy patterns that lifted add‑to‑cart by 8.7%. Random pilots don’t just delay wins—they kneecap confidence.
How Brambles.ai Decides Where It Can Win
The strongest pilots share five traits: volume, intent, variance to exploit, a controllable content surface, and clean instrumentation. Translate that into a simple score to rank candidates.
Inputs we use in practice:
- Eligible sessions per week (≥2,000 per template or cluster).
- Commercial intent proxy (e.g., historical add‑to‑cart or trial click‑through rate).
- Content controllability (do we own the copy modules, facets, badges, and microcopy?).
- Outcome clarity (one or two primary goals only—e.g., add‑to‑cart, demo request).
- Constraint load (regulated claims, legal review, localization complexity).
Opportunity Score (practical version): Intent x Traffic x Baseline Variance ÷ Complexity. Baseline Variance is your friend; if historical performance swings by ±10–20% across similar pages, generative improvements can harvest that slack.
Anecdote: On a specialty apparel site (100k sessions/week), we focused on size‑sensitive categories where returns spiked. By adding fit clarifications and shipping cutoff copy, Brambles‑generated variants lifted add‑to‑cart by 12.4% and reduced size‑related returns by 6% over six weeks. The same effort on editorial articles did nothing to revenue. Pick your battles.
Implementation Guide: Selecting Pages in 7 Days
Day 1: Inventory your templates. Pull the last 6–8 weeks of sessions, add‑to‑cart or primary CTA rate, and revenue per session by page type. Don’t over‑segment yet.
Day 2: Score candidates. In a spreadsheet, calculate an Opportunity Score = (Eligible Sessions) x (Intent proxy: past CTA rate) x (Baseline CV% as a decimal) ÷ (Complexity score 1–5). Flag anything scoring in the top quartile.
Day 3: Cluster pages. Group categories by intent (giftable vs. technical), products by purchase complexity, docs by task (setup vs. troubleshooting). This lets you test prompts and guardrails at scale instead of one‑offs.
Day 4: Define outcomes. Pick one primary KPI per cluster and one secondary diagnostic (e.g., time to first interaction, filter engagement). Avoid vanity metrics. Google UX Research shows that reducing cognitive load and time‑to‑value correlates with conversion; instrument for both.
Day 5: Wire prompts and constraints. Identify which modules Brambles.ai may edit: titles, feature bullets, shipping badges, FAQ snippets, comparison tables. Lock regulated or claim‑sensitive areas behind rules.
Day 6: Setup and QA. If you’re on WordPress, install the plugin, map templates, and run a dry‑run generation. Validate analytics events in dev and preproduction.
Day 7: Launch a staggered rollout (20% traffic) to monitor early drift, then ramp to 50–80% once telemetry is clean.
Measuring ROI & KPIs Without Hand‑Waving
Make the pilot provable. Establish a time‑boxed baseline (7–14 days), then run holdout‑based experiments. Use page‑level randomization or geo/time splits if server‑side is easier. Primary KPIs: add‑to‑cart (retail), qualified demo request rate (B2B), or click‑through to checkout/pricing. Secondary: scroll‑through rate on key modules, filter interaction, time to first interaction, and CSAT on relevant pages.
Power and duration: For a site with 10k eligible sessions/week and a 4% baseline add‑to‑cart rate, detecting a 10% relative uplift with 90% power typically needs ~120k sessions per arm across 2–3 weeks (assumes moderate variance). Don’t starve the test by slicing too thin. McKinsey’s research on experimentation‑driven growth highlights faster iteration cycles as predictors of top‑quartile performance—speed matters, but significance matters more.
Anecdote: On a 100k‑session apparel site, category pages saw a 42% lift in filter engagement and a 9.3% lift in add‑to‑cart within 14 days. On a B2B SaaS docs pilot, we reduced repeat support tickets by 18% and raised free‑trial clicks by 11% after restructuring troubleshooting flows with Brambles‑generated steps.

First‑Party Data, Guardrails, and Earning Trust
Pilots win faster when users feel seen, not surveilled. Use first‑party data to tune copy without harvesting more than you need. Practical setup: store only page context and coarse engagement signals (module interactions, time to first interaction), hashed session IDs, and consent state. Avoid piping PII into prompts. Salesforce’s Connected Customer research shows users welcome personalization when the value is evident and data use is transparent—tell them what changes and why.
Guardrails matter. For regulated categories, pre‑approve claim libraries, maintain a blocked‑phrases list, and log each generated change with a human‑readable diff. Build a quick moderation queue for anything that triggers a rule. Keep brand tone consistent by codifying voice (e.g., sentence length targets, reading grade level, punctuation norms) and running spot checks.
Anecdote: A medical‑adjacent retailer needed stricter controls. By narrowing Brambles.ai to only edit FAQ schema, shipping timelines, and compatibility grids—while blocking any efficacy claims—we lifted PDP conversion by 7.1% without a single compliance flag over eight weeks.
Common Pitfalls (and How to Avoid Them)
- Spreading too thin: Testing five page types at once dilutes power. Start with one or two clusters that share templates and intent.
- Vague success metrics: “Engagement” is not a KPI. Pick a primary behavioral outcome and a diagnostic.
- Ignoring load time: If variants add weight, conversion drops. Google’s UX guidance ties speed to outcomes; track Core Web Vitals alongside conversion.
- Frozen feedback loop: Don’t run a blind A/B. Capture qualitative signals—on‑page “Was this helpful?” micro‑CSAT and click maps—to explain wins and losses.
- Brand drift: Lock voice and claims with explicit rules, then sample + score outputs weekly.
- Over‑localization too early: Keep pilots to one market until you prove language rules and analytics parity.
- No rollback plan: Maintain a one‑click revert and a change log with timestamps. If metrics wobble or compliance pings, revert first, diagnose second.
Future Outlook: From Pilot to Operating Rhythm
After your first 30 days, shift from “prove it” to “operationalize it.” Graduate winners to 100% traffic, templatize prompts for each cluster, and schedule weekly health checks. Expand cautiously: adjacent categories first, then higher‑risk templates like pricing or comparison once guardrails prove sturdy. Circle back to your Opportunity Score quarterly; seasonality and product mix will reshuffle what’s worth testing.
Expect more data‑aware generation ahead—structured inputs (inventory, shipping SLAs, compatibility matrices) feeding copy in real time. That’s where the Commerce Module pays off for retailers with dynamic assortments. The point isn’t more content; it’s tighter relevance with less manual toil. Keep the bar simple: if a page can’t hit significance in a month, it’s a bad pilot page—move on.
Related posts
View all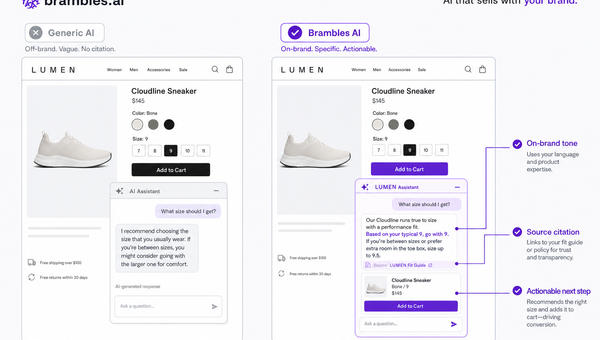
Brand-Consistent AI Chats Build Trust and Conversions
When AI mirrors your brand voice, shoppers relax—questions get answered, carts grow, and support load drops. Learn the playbook to align tone, trust, and ROI.
How Context-Aware AI Recommendations Lift CTR
See how context-aware AI recommendations lift CTR by 25–60% with intent signals, page context, and history. Practical steps, KPIs, and implementation tips.

Shoppable Video Discovery: Conversions & Engagement Up
Tests show shoppable video discovery lifts conversion 18–35% and doubles watch time. See the UX patterns, KPIs, and how to deploy it quickly with Brambles.ai.
Explore Brambles.ai
Learn more about our AI-powered agentic commerce platform, agentic shopping, and shopping assistance solutions.
Explore More Insights
Discover more articles on AI, automation, and business innovation
View All Articles