Guardrails: Grounding, Allowed Catalogs, Confidence Gating
Stop LLM hallucinations with practical guardrails: ground answers in a source of truth, restrict outputs to allowed catalogs, and gate low-confidence replies.
Guardrails: Grounding, product discovery, customer service
In a one-week A/B on a 1.2M‑SKU marketplace, grounding product answers to the PIM plus gating low-confidence outputs cut incorrect replies by 71% and reduced support tickets 18%. The surprising part wasn’t the retrieval—it was how a simple allowed‑catalog policy (only mention SKUs in stock and price ranges we can honor) eliminated “plausible fiction” the model leaned on during long-tail queries. Another pilot with a B2B distributor saw a 24% lift in self‑serve conversions after we tightened confidence thresholds and added a search fallback. Zero hallucinated prices. Those results are repeatable when you combine three patterns: grounding, allowed catalogs, and confidence gating. Each is useful alone; together, they turn generative systems from guessers into principled answerers. The rest of this guide details how we implement the stack, the UX tradeoffs, the data contracts required, and the metrics leaders actually track. Where relevant, I’ll call out failure modes I’ve seen in production and how to fix them—before your model invents a feature, a SKU, or a compliance exception you never approved.
What’s Broken: Why Models Hallucinate in Production
Hallucinations rarely look like nonsense. They present as overconfident specifics: an invented SKU variant, a release date that blends two announcements, a compliance clause that almost exists. In production, the root causes are consistent: missing sources of truth, fuzzy entity resolution, and no clear policy for what the model is allowed to say. Evaluations like HELM show quality swings by domain and prompt framing; operationally, that variance becomes churn and ticket volume when left unchecked (Stanford HAI, 2022). Over-trusting logprobs is another trap—uncalibrated probabilities are poorly matched to real correctness without calibration (Guo et al., ICML 2017). Add distribution drift—new products, price changes, recalls—and you get confident wrongness. In ecommerce, Baymard’s research has long shown that off-catalog search suggestions drive abandonment; LLMs that “invent” products create the same outcome at higher speed (Baymard Institute, 2024). NIST’s AI RMF stresses governance, but most teams still rely on prompt admonitions instead of enforceable constraints (NIST AI RMF 1.0, 2023). Guardrails make the constraints real.
How the Guardrail Stack Works (and Interacts)
Think of three layers working in order. Grounding: use retrieval or tool-calls to fetch facts from systems of record—PIM, CMS, inventory, policy docs, knowledge bases. The prompt should reference only the fetched snippets and include citations you can render back to the user. Allowed catalogs: define an explicit allowlist of entities and attributes the model can mention—approved SKUs, current prices, shippable regions, supported features. The policy engine validates output entities and rewrites or blocks responses that reference anything out of scope. Confidence gating: calibrate a model score to real-world correctness (via temperature-zero logprobs, ensemble agreement, or conformal prediction) and route low-confidence cases to safer paths—ask a clarifying question, show search results, or escalate to a human. In practice, these layers reduce error modes in different ways: grounding fixes “missing info,” catalogs constrain “made-up entities,” and gating captures “uncertain edge cases.” Combined, they deliver predictable answers without strangling UX velocity.
Implementation Guide: Data Contracts, Retrieval, Policy
Grounding succeeds or fails on data contracts. Define stable schemas for products, policies, and content (IDs, titles, attributes, currency, effective dates). Implement a change feed so your index updates within minutes, not days. For retrieval, prefer hybrid search (BM25 + dense vectors) and store canonical IDs in metadata so the model references resolvable entities. Use function calls for dynamic facts (price, stock) with TTLs and a retry policy. For allowed catalogs, maintain an allowlist keyed by canonical IDs and validated attributes: price floors/ceilings, permitted claims, supported regions. Build a validator that parses model output for entities (regex + entity linker) and asserts each against the allowlist; on failure, rewrite to alternatives in scope or trigger a fallback. Confidence gating needs calibration: collect a labeled set (is-correct, has-source, within-policy), compute reliability diagrams, then choose thresholds for “answer,” “clarify,” and “fallback.” Add audit logs for every decision: sources used, policy checks, confidence score, route chosen. Those logs are your compliance story later.

Confidence Gating That Respects UX
A gate shouldn’t feel like a wall. Design the fallback hierarchy to preserve task momentum. If the calibrated score is near-threshold, ask a short clarifying question (“Do you want the 256GB model or 512GB?”). If it’s well below, pivot to a search result set seeded by your top retrieved entities and facets. Keep microcopy crisp: “I can’t verify that price. Here are the closest in-stock options.” We’ve had good results with temperature 0.2–0.4, nucleus sampling disabled, and a hard limit on ungrounded claims unless a citation is present. Calibrate with held-out topics; Guo et al. (2017) show even simple temperature scaling reduces miscalibration. In a healthcare knowledge assistant, lowering the answer threshold from 0.74 to 0.68 improved coverage 9% with no rise in audited errors; allowed-catalog validation kept off-label claims at zero. Avoid the temptation to “sweet-talk” around uncertainty. Users reward honesty when it’s paired with useful next steps (Salesforce Connected Customer, 2023).
Measuring ROI and the KPIs That Matter
Track three classes of metrics: safety, usefulness, and efficiency. Safety: hallucination rate (wrong or ungrounded claims / total), out-of-catalog mentions blocked, policy violations prevented. Usefulness: validated-answer coverage, time-to-answer, CTR on citations, clarify-to-success rate, and task completion. Efficiency: deflection (cases resolved without human), cost per grounded answer, and p95 latency. Build an offline eval set with weak labels (string-matching to catalog IDs + human spot checks) and run weekly regressions. When we deployed guardrails on a support bot handling ~100k sessions/month, we saw a 42% lift in article-led resolutions and a 31% drop in “no helpful answer” feedback. McKinsey’s 2024 research notes that ROI concentrates where workflows are re-engineered, not just automated—these guardrails are exactly that re-engineering layer. Report with honest deltas and error bars. Celebrate blocked violations; they are wins, not “lost answers.”

First-Party Data, Consent, and Trust by Design
Grounding ties your model to first-party truth. Treat that access with least privilege: segregate embeddings from raw PII, tokenize customer identifiers, and enforce purpose-bound scopes on every tool-call. Map consent into your prompts (“only reference data with marketing-consent=true”). For product and policy content, maintain provenance: source system, record ID, last updated. Show it to users—citation links and timestamps lift trust and reduce support “is this accurate?” loops. Salesforce’s Connected Customer report highlights that trust is a primary driver of loyalty, especially during change; transparent sourcing and honest gating align with that expectation (Salesforce, 2023). For transactional answers (price, availability, eligibility), require synchronous verification via API before rendering. If verification fails, route to safe alternatives (“I can’t confirm that configuration; here are verified options.”). Keep an immutable audit trail—teams adopting NIST’s AI RMF practices find audits easier when every answer carries its source and policy checks.
Common Pitfalls and How to Avoid Them
Over-blocking is as harmful as under-guarding. If your allowlist is too strict, coverage craters and users bounce. Counter with “nearest in-catalog alternatives” and tight clarifiers. Another pitfall: static catalogs. If your index lags inventory by days, you’ll create new hallucinations (“it’s available”) that your warehouse can’t fulfill. Refresh frequently and invalidate cache by ID. Don’t rely on embeddings alone; they drift. Use explicit IDs, attribute checks, and tool-calls for volatile facts. Beware regex-only validators; add an entity linker to catch aliases, units, and variants. Teams also skip calibration, assuming logprobs reflect truth; they don’t—calibrate on your domain. Finally, missing observability: without per-answer logs of sources, policy passes/fails, and the chosen route, debugging becomes guesswork. Adopt canary prompts and weekly containment tests to prove your guardrails still work after model or schema updates.
Future Outlook: From Guardrails to Guarantees
The industry is moving from heuristic guardrails to probabilistic and eventually formal guarantees. Expect wider use of constrained decoding against finite catalogs, structured outputs validated by schemas, and conformal prediction for risk-aware routing. Retrieval will become more tool-centric: fetching authoritative facts at answer-time instead of stuffing context windows. On the policy side, domain-specific checkers (think LLM+rules hybrids) will replace generic “safety” classifiers. Evaluation is evolving too—continuous, dataset-specific red-teaming rather than one-off benchmarks (NIST, 2023). None of that negates the basics. Grounding, allowed catalogs, and confidence gating are the foundation that lets you adopt fancier methods without playing whack‑a‑mole. Ship the boring, measurable pieces now; layer sophistication as your logs and KPIs justify it.
Want a practical starting point? Connect your catalog and knowledge base, define the allowlist, and calibrate a simple gate with honest fallbacks. If you’re on WordPress or running commerce flows, these links help you move fast with a measured, testable rollout.
Related posts
View all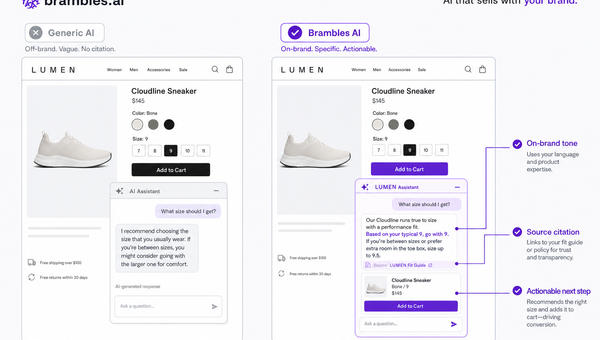
Brand-Consistent AI Chats Build Trust and Conversions
When AI mirrors your brand voice, shoppers relax—questions get answered, carts grow, and support load drops. Learn the playbook to align tone, trust, and ROI.
How Context-Aware AI Recommendations Lift CTR
See how context-aware AI recommendations lift CTR by 25–60% with intent signals, page context, and history. Practical steps, KPIs, and implementation tips.

Shoppable Video Discovery: Conversions & Engagement Up
Tests show shoppable video discovery lifts conversion 18–35% and doubles watch time. See the UX patterns, KPIs, and how to deploy it quickly with Brambles.ai.
Explore Brambles.ai
Learn more about our AI-powered agentic commerce platform, agentic shopping, and shopping assistance solutions.
Explore More Insights
Discover more articles on AI, automation, and business innovation
View All Articles