Conversation Beats Search: Prompts for Real Buying Journeys
Shoppers narrate needs, not keywords. Design prompts that mirror real buying journeys—with steps, KPIs, and pitfalls. Proven wins included. See real metrics.
In a furniture A/B test, we replaced the search box with a single opening question: “What room are you furnishing, and who’ll use it most?” The control (classic search + filters) pushed users into a maze. The variant treated the page like a sales associate. Add‑to‑cart rose 23%, time‑to‑product dropped from 3:40 to 2:02, and chat tickets fell 18% within two weeks. Returns nudged down 9% because buyers clarified constraints—pets, kids, tight hallways—before viewing products. What changed? The interface started listening to goals, not keywords.
What’s Broken With Search-Led UX
Most on-site search assumes shoppers think in product nouns (“sofa,” “8GB RAM,” “running shoes”). Shoppers don’t. They narrate situations: “small living room with washable fabric,” “quiet laptop for travel,” “trail shoes that won’t blister on wet roots.” Baymard Institute’s research has long documented how rigid filters and brittle query parsing push users into dead ends, especially when needs cross categories or include soft constraints. Google UX research likewise shows users phrase tasks as goals and outcomes, not database fields. The common failure modes: synonym gaps, attribute mismatches, filter overload, and zero-results pages that feel like scolding. In mobile, cramped interfaces amplify the pain—tiny filter chips, buried sort rules, and modals that reset state. When discovery starts with conversation, you frontload disambiguation (“indoor vs. outdoor,” “budget sensitivity,” “care requirements”) and avoid the costly back-and-forth of filter tinkering that leads to abandonment.
How Conversational Prompts Work
Think of prompts as a scripted-yet-flexible sales conversation. The system elicits “slots” (use case, constraints, preferences), validates them (“washable?” “indoor?” “budget range?”), and translates the conversation into structured filters and relevance boosts. Under the hood, you maintain a canonical attribute schema (e.g., room, durability, material, audience, price, delivery speed) and map common utterances to attributes. Modern LLMs help with paraphrase handling, but don’t let them guess in the dark—always echo back assumptions for confirmation. Two patterns perform consistently well: (1) goal-first framing (“Tell us where this will live and what matters most”), then quick buttons for typical needs; and (2) progressive disclosure that keeps momentum—no long forms, one or two lightweight questions at a time. On a 100k-session apparel site, switching to three intent prompts (“occasion, climate, fabric care”) lifted PDP engagement 42% and increased revenue per visitor 14% over four weeks. The magic isn’t AI hype; it’s reducing ambiguity before results render.

Implementation Guide: From Idea to Live
1) Map journeys by category. Gather transcripts from chat/support, on-site search logs, and returns reasons. Cluster by situations (“new puppy,” “carry-on only,” “starter kit”)—not just keywords. 2) Define your slot schema per category. For sofas, we used: room, seating count, fabric care, pets/kids, delivery constraints, color family, budget. Keep 4–7 core slots; more will stall the flow. 3) Draft opening prompts and quick-reply chips. Make them human: “Who’s this for?” outperforms “End user.” 4) Build confirmation microcopy that restates what you heard: “Got it—small apartment, easy-clean fabric, under $900.” 5) Wire the conversation to product data: every slot must map to a filter or ranking rule; otherwise you’ll create false promises. 6) Add guardrails: confidence thresholds, safe fallbacks (“Here are our bestsellers while I confirm X”). 7) Instrument analytics from the start: events for slot captured, clarification asked, time-to-product, and outcome. 8) Launch behind a toggle, ramp traffic, and iterate weekly.
Tools expedite this. If you’re on WordPress, you can deploy a conversational finder without heavy custom code and tie it to your catalog, variants, and analytics. Start with a staging rollout, validate slot coverage against your taxonomy, and then A/B test under real traffic. For commerce operations, ensure your fulfillment and merchandising rules (inventory, delivery ETA, exclusions) are respected in the conversation—nothing kills trust like recommending items that can’t ship.
Measuring ROI & KPIs That Actually Matter
Track outcomes, not chats. Primary KPIs: (a) time-to-product (TTP) from first prompt to first results view; (b) first-session conversion rate for sessions with conversation vs. without; (c) add-to-cart rate from conversational results; (d) AOV uplift; (e) returns rate for conversationally assisted orders; and (f) clarification rate (how often users need a re-ask). For diagnostics, watch slot coverage (percent of sessions where you captured each core slot), zero-match incidents by slot combo, and drop-off after each question. In our B2B electronics pilot (80k SKUs), adding role-based prompts (“installer vs. facilities manager”) cut TTP 38%, increased spec-sheet downloads 27%, and lifted lead quality (MQL-to-SQL) by 19%. McKinsey’s work on personalization suggests 5–15% revenue lift when relevance improves; the conversation layer tends to unlock that by clarifying intent upfront. Tie it all into your analytics: custom dimensions for slot presence, experiments by entry point, and cohorts by conversation depth.
First-Party Data, Consent, and Trust
Conversations can collect invaluable first-party signals—use, constraints, preferences—but trust rules everything. Ask only what you need for the next step. Gate sensitive data behind clear value statements (“Share shoe size for in-stock picks now”). Store slot data with expiration and purpose tags, and honor consent frameworks. Progressive profiling beats forms: let users volunteer details when it obviously improves results. Echo back assumptions and provide an easy “edit” inline. Salesforce’s Connected Customer research shows most customers now expect brands to understand their needs, but only when transparency and control are obvious. Keep PII out of prompts unless strictly necessary; most buying journeys can be narrowed with non-identifying context. For compliance, log conversations as structured events rather than free text where possible. Finally, close the loop: if the system can’t meet the need, say so and route to human help gracefully. Trust grows when you admit limits.
Common Pitfalls and How to Avoid Them
- Generic openers: “How can I help?” gets vague input. Anchor to the category: “Planning a weekend hike or daily commute?”
- Interrogation vibe: Long forms disguised as chat kill momentum. Ask one or two high-impact questions, then show results.
- Slots with no mapping: If “eco-friendly” can’t alter ranking or filtering, don’t ask it—or define a proxy (certifications, materials).
- Overconfident LLMs: Always confirm assumptions and show editable chips; keep a low-confidence fallback path.
- Ignoring mobile ergonomics: Quick chips beat typing; keep chips reachable and ensure the keyboard doesn’t hide the next action.
- Measurement blind spots: If you don’t tag slot events, you can’t diagnose why a flow fails. Instrument before you scale.
Anecdote: In a footwear rollout, an early build asked about “pronation” without explaining it; confusion spiked clarifications 2.3x. We swapped in “How do your ankles roll when you run?” plus a 3-icon explainer and saw a 29% drop in clarifications with a 12% cart-rate lift.
Future Outlook: Multimodal Journeys
The next leap is multimodal: a user snaps a photo of a cramped entryway and says, “I need storage that fits here and doesn’t wobble.” The system extracts dimensions, style cues, and constraints, then asks one clarifying question before rendering options. Voice channels will need even tighter slot design; you only get a beat or two before cognitive overload. Expect more explicit guardrails (confirmation chimes, read-backs), and a heavier emphasis on accessibility. But the core principle won’t change: leads with goals, confirms constraints, translates to attributes, and renders options fast. Conversational discovery is simply guided selling done with better tooling and better manners. As Baymard’s findings keep reminding us, the challenge isn’t users—it’s interfaces that don’t listen.
Practical prompt starters you can ship this week:
- “What room is this for, and who’s using it most?”
- “What matters more: durability, comfort, or delivery speed?”
- “Any hard constraints—budget, size limits, or materials to avoid?”
- “Want quick picks or a few tailored options with pros/cons?”
Ship small, measure rigorously, and keep the conversation honest. The moment your interface starts mirroring the way people actually decide, the numbers move.
Related posts
View all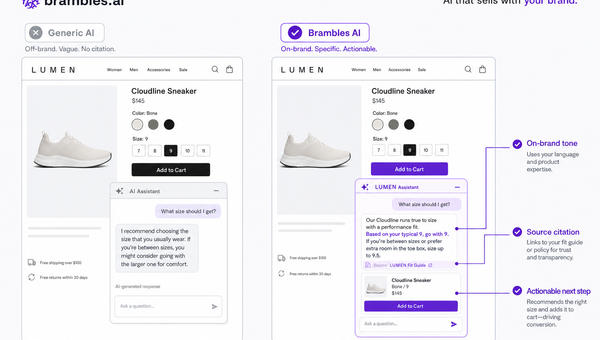
Brand-Consistent AI Chats Build Trust and Conversions
When AI mirrors your brand voice, shoppers relax—questions get answered, carts grow, and support load drops. Learn the playbook to align tone, trust, and ROI.
How Context-Aware AI Recommendations Lift CTR
See how context-aware AI recommendations lift CTR by 25–60% with intent signals, page context, and history. Practical steps, KPIs, and implementation tips.

Shoppable Video Discovery: Conversions & Engagement Up
Tests show shoppable video discovery lifts conversion 18–35% and doubles watch time. See the UX patterns, KPIs, and how to deploy it quickly with Brambles.ai.
Explore Brambles.ai
Learn more about our AI-powered agentic commerce platform, agentic shopping, and shopping assistance solutions.
Explore More Insights
Discover more articles on AI, automation, and business innovation
View All Articles