
Clean Matches, Happy Shoppers: ASIN/UPC Normalization
Fix mismatched SKUs before they wreck CX. Learn how ASIN/UPC normalization de-duplicates catalogs, & lifts conversion with clean product identity faster.
On a spring promo week, we audited two “competing” blenders that kept leapfrogging each other in site search. Same photo, same wattage, same reviews—different ASINs. The duplicate soaked up ad budget, split reviews, and confused shoppers. After we normalized identifiers (ASIN to UPC/GTIN and brand+MPN), the winning product consolidated, product discovery and search CTR climbed 11%, and returns dipped because buyers finally knew which model they were getting. A few weeks later, a mid-market electronics client rolled the same playbook across 28k SKUs and recovered 6.2% revenue from cleaned price comparisons alone. The lesson is simple: content intelligence for clean matches make happy shoppers—and cleaner P&L.
What’s Broken: ASINs, UPCs, and Variant Chaos
Catalogs break in boring, expensive ways. Marketplace-created ASINs drift from manufacturer barcodes; third-party sellers spin orphan ASINs; UPC-A vs EAN-13 leading zeros disappear in spreadsheets; bundles and multipacks are treated like single units; and brand fields explode into permutations ("P&G", "Procter & Gamble", "Procter and Gamble"). We’ve seen the same SKU appear as a 12-pack on one channel and a single unit on another—with identical titles. Baymard Institute’s large-scale usability research has long shown that inconsistent specs and naming muddy comparison tasks and push users to postpone decisions. Add scraped titles, bad casing, and ghost attributes, and you get apples-to-oranges results that erode trust. Teams often chase a single silver-bullet key and miss the reality: identity lives in a bundle of signals—UPC/GTIN, brand, MPN, dimensions, variant axes, and unit-of-measure. Without a disciplined normalization layer, your shoppers, ads, and analytics argue about what is actually the same product.
How Normalization Works: From Signals to a Canonical ID
A robust pipeline treats “match” as a clustering problem with evidence. Ingest product feeds from marketplaces, PIM, and vendor catalogs. Normalize fields (trim whitespace, titlecase brands, standardize units). Promote trustworthy keys—GTIN-14 from UPC/EAN, brand, MPN—and demote noisy ones—free-text titles, marketing copy. Block candidates using cheap keys (e.g., normalized brand + MPN, or GTIN when present) to reduce compute. Within each block, score matches with layered logic: deterministic (exact GTIN or brand+MPN), rule-based heuristics (pack-size regex: “x-pack”, “count”, “ct”, “multipack”), then semantic similarity (TF‑IDF or embeddings on title/specs). Build a variant graph so size/color multipliers cluster under a parent canonical. Apply survivorship rules: prefer manufacturer dimensions and GS1-validated GTIN, choose majority image, and reconcile per-unit price. Every decision should carry provenance: which field from which source, when. The outcome is a canonical product ID with lineage to all contributing records, not just a deduped title.
Implementation Guide: A 30–60 Day Rollout Plan
Week 1–2: Inventory your identifiers. Measure coverage for GTIN/UPC, brand, MPN, variant axes, pack size, country of sale. Create a normalization dictionary for brands and units (oz ↔ fl oz ↔ fluid ounce; kg ↔ g). Flag high-risk categories (health/beauty, grocery, electronics accessories) where counterfeits and multipacks are common. Establish ground truth with 200–500 manually audited SKUs to tune thresholds. Week 3–4: Implement blocking and rules in your warehouse. Example rules: if GTIN exact match and brand normalized within whitelist, auto-merge; if brand+MPN exact but pack sizes differ, do not merge—propose variant under parent. Use regex to parse multipacks (“(\d+)[- ]?(pack|ct|count)”). Add a classifier to detect “bundle” words (with, +, kit). Week 5–6: Add a semantic pass using embeddings for near-duplicates; cap merges by requiring at least one strong key (GTIN or brand+MPN) to avoid fuzzy-only overreach. Launch human-in-the-loop review for borderline scores (e.g., 0.72–0.84). Ship daily deltas, not full rebuilds, to keep feeds stable.
Two small but mighty tips from the field: first, version your dictionaries and label every match with the rule that fired—your auditors and future self will thank you. Second, don’t bury normalization behind your PIM; expose a read-only “cluster card” in your admin with lineage so merchandising, search, and ads teams work from the same truth. If you operate on WordPress, connect your product feed to a normalization service and keep outputs synced to your search index and ad destinations. We’ve seen teams pipe normalized catalog data into retail media feeds and watch CPCs settle as duplicate keywords stop competing against themselves.
Measuring ROI: From Dedupe Rate to Retail Media ROAS
Treat identity like a product with KPIs. Track match precision/recall against your ground truth. Monitor cluster purity (how often variants are grouped correctly), dedupe rate (pre vs. post unique SKUs), and coverage of trusted keys (GTIN, brand, MPN). On the shopper side, watch search CTR, PDP bounce rate, add-to-cart from comparison modules, and per-unit price views. For ads, monitor retail media ROAS, CPC, and keyword cannibalization. One apparel marketplace that adopted this framework consolidated 18% of their catalog into canonical clusters and saw a 22% ROAS improvement over six weeks as duplicate ad sets were retired. Another test on a 100k-session appliances category reduced PDP exits by 9% when we clarified multipacks and standardized per-unit pricing. Google UX Research emphasizes that clear comparison scaffolding lowers cognitive load; our dashboards tend to show that translate to faster path-to-cart. Report weekly: a single page with purity, precision, revenue from deduped price comparisons, and ad waste prevented.
First-Party Data, GS1, and Shopper Trust
Normalization gets easier—and more credible—when you anchor to first-party truth. Pull GTINs from invoices and ASN labels, not just scraped titles. Validate ranges against GS1 and flag anomalies (invalid check digits, country prefixes out of scope). Use warranty registrations and return reasons to catch over-merges (e.g., customers report “wrong size received” for a cluster—often a variant conflation). Salesforce’s Connected Customer research points out that trust is cumulative across touchpoints; clean identity pays off in the quietly powerful ways: consistent review counts, accurate per‑unit pricing, and comparison tables that agree across channels. Show your work to shoppers: a “Same product? Compare sellers” module tied to your canonical ID lets users inspect differences transparently. For grocery and health, surface unit-of-measure equivalence (per 100g, per fl oz) so the apples-to-apples claim isn’t just internal—it’s visible and legible on the page.
Common Pitfalls That Derail Matching
Over-merging is worse than under-merging. If you combine a 6‑pack with a single unit or collapse region-specific models, you corrupt reviews and pricing signals. Avoid fuzzy-only merges; require at least one strong key. Don’t forget leading zeros in UPC/EAN conversions or assume that every seller uses a manufacturer’s true MPN. Keep a separate "case pack" field so wholesale packaging doesn’t collide with each unit listing. Maintain temporal awareness: manufacturers reissue GTINs, and marketplaces merge or split ASINs over time—your clusters need versioning and effective dates. Finally, store evidence. When merchandising disputes a merge, you should be able to show the GTIN validation, the brand normalization dictionary entry, the multipack regex hit, and the similarity score that justified the decision. Baymard’s guidance on spec consistency and Google’s research on comparison UX both echo the same theme: clarity comes from disciplined structure, not clever titles.
Future Outlook: GS1 Digital Link and a Universal Product Graph
GS1 Digital Link is pushing identifiers onto the web as resolvable URLs, which will make identity more portable and verifiable. Expect vendors to ship canonical metadata with barcodes, shrinking the gray zone where sellers invent ASINs. On the matching side, embeddings will keep improving, but organizations that win will still ground models in deterministic anchors: GTIN, brand, MPN, and explicit variant axes. Schema.org/Product markup will feed search engines a cleaner product graph, and retail media networks will increasingly require match evidence to attribute conversions across sellers. We’ve started tying warehouse identity clusters to a “compare anywhere” component so the same canonical product renders in search, PDP bundles, and ads. When buyers can inspect the lineage—why listings are considered the same—trust follows. That’s the endgame: a universal product graph that lets shoppers make quick, confident, apples-to-apples choices and lets businesses measure with less noise.
Practitioner notes worth stealing: when we tuned a home goods catalog, locking merges behind GTIN or brand+MPN and treating embeddings as tie-breakers preserved 97% cluster purity in audit. And a marketplace that exposed a moderator queue for 0.75–0.85 match scores cleared 1,200 borderlines in a week with two part-time merchandisers—because evidence was contextual and reversible.
If you want to operationalize this quickly, pair your normalization pipeline with publishing hooks to your CMS and ad channels. That way, clean identity instantly powers site search, comparison modules, and retail media feeds without waiting on a full PIM overhaul.
Related posts
View all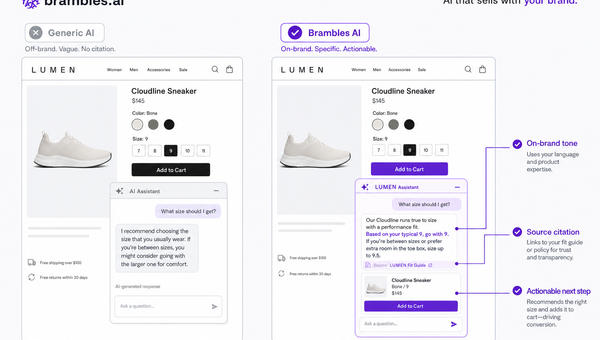
Brand-Consistent AI Chats Build Trust and Conversions
When AI mirrors your brand voice, shoppers relax—questions get answered, carts grow, and support load drops. Learn the playbook to align tone, trust, and ROI.
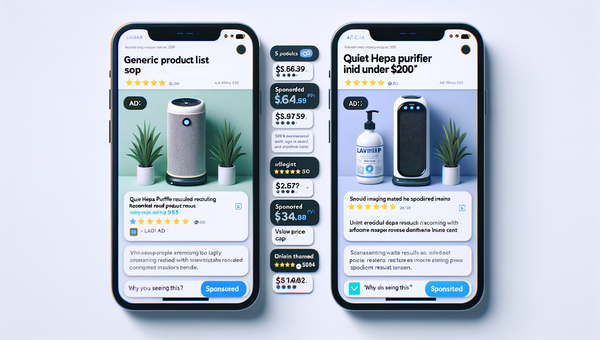
Sponsored Products in AI Shopping: Retail Media 101
Learn how sponsored product placements power AI shopping, how bidding and relevance work, and how to implement retail media without eroding trust or UX.
How Context-Aware AI Recommendations Lift CTR
See how context-aware AI recommendations lift CTR by 25–60% with intent signals, page context, and history. Practical steps, KPIs, and implementation tips.
Explore Brambles.ai
Learn more about our AI-powered agentic commerce platform, agentic shopping, and shopping assistance solutions.
Explore More Insights
Discover more articles on AI, automation, and business innovation
View All Articles